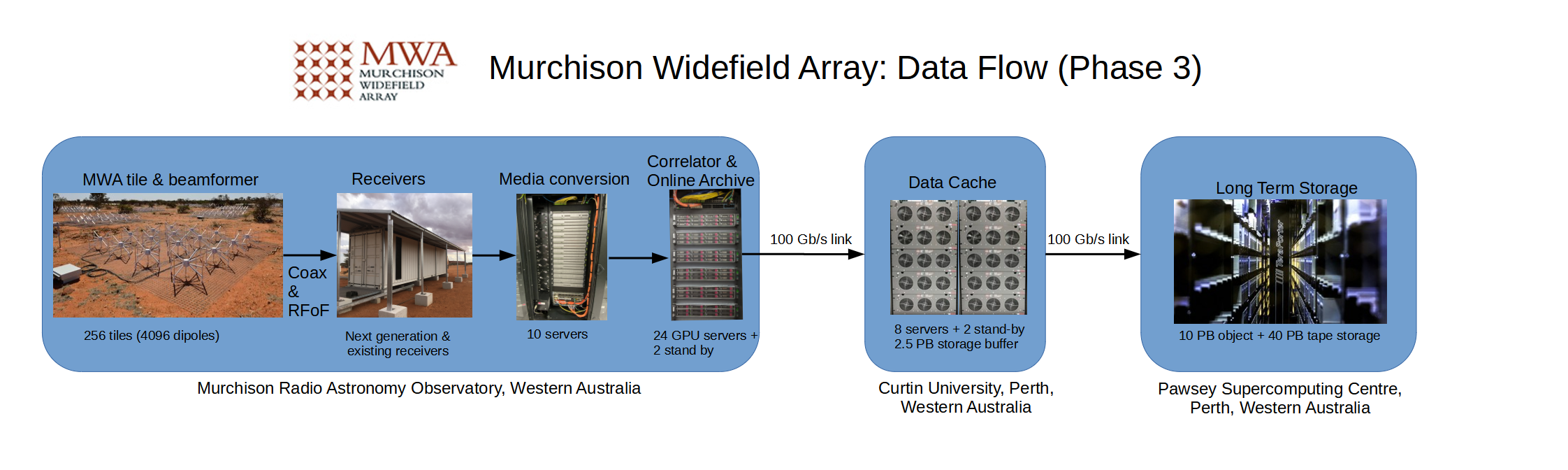
The MWA data archive is located in Perth at the Pawsey Supercomputing Research Centre, and is comprised of two systems named Acacia and Banksia.
Acacia is a 60PB disk-based storage system, of which 10PB is reserved for use by the MWA. Banksia is a 70PB tape storage system, with 40PB being reserved for use by the MWA. Therefore, the total available space for the MWA archive is 50PB, or 50 million gigabytes.
Data are provided to the international astronomy community via the MWA node of the All-Sky Virtual Observatory (MWA ASVO). Here, researchers are able to browse a complete history of all observations ever taken by the telescope, with the ability to drill down by user-specified criteria. Users then submit job requests to the MWA ASVO, which extracts and provides the relevant data from the archive.
MWA ASVO
Significant processed data products produced by the MWA Collaboration (such as the initial release of the GLEAM survey) are also available via various international scientific databases for analysis and interpretation.
Once MWA data are processed and analysed by astronomers, the outputs are often published in peer-reviewed journals. We keep track of the papers produced by members of the MWA Collaboration, which can be viewed at the link below.
MWA Papers Library